古文字是中华文化的根脉,对于当代中国文化建设的意义不言而喻。但是古文字学尚属冷门“绝学”,古文字对古文字学科外的绝大多数人来说还是“天书”,古文字学的知识系统对社会大众来说还是锁在象牙塔里的“秘籍”。
互联网的信息传输方式,使得各种专业知识传播的便利程度发生了革命性改进,古文字学要走出冷门,数字化也是必由之路。然而,数字化必须以字符集为支撑平台,古文字数字化的大戏自然也需要古文字字符集来搭台。令人遗憾的是,目前通用的中文电脑字符集中尚无古文字字符集这块拼图。这一现状除了会阻遏古文字数字化的发展外,也会导致人们对古文字字符集的作用缺乏准确的认识,进而拉低人们研制古文字字符集的紧迫感。在古文字学各研究方面中,古文字字符集的研制显然又成为冷门中的冷门。这种消极的因果循环,大大拖慢了古文字数字化的进程。而改变这种现状,需要我们准确认识古文字字符集及其不可或缺的存在意义。
什么是古文字字符集
古文字字符集不是一般意义上的古文字字体,虽然字符集在电脑中的显示需要通过字体来实现,但目前很多所谓古文字字体呈现的字符集并不能称为“古文字字符集”。“古文字字符集”必须能够系统支持古文字数字化,因此它首先必须满足三个要求。第一,古文字字符集要集合起古文字所有具有存在必要的字符,并逐一为它们分配现行标准电脑字符集的唯一编码。第二,古文字字符集中所有的字符,必须能逐一覆盖实际古文字材料中所有的对应用字,换言之,就是让所有的古文字文献用字都被赋予标准字符集的编码。第三,对应古文字字符集中所有的字符,逐一建立属性信息系统,这些信息包括字符层级的、输入检索的、材料来源的、释读研究的,等等。
本文所说的“古文字字符集”,不仅指正式进入电脑字符集国际标准的古文字字符集,也包括按上述标准研制的可以在局域范围营造数字标准进而支持古文字数字化的字符集。就现实情况来说,古文字字符集真正被电脑字符集国际标准接受尚待时日,但是我们并不能因为这样的现实而放弃按国际标准来打造我们的古文字字符集。这既是古文字数字化的现实需要,也是最终推动古文字进入电脑字符集国际标准的必由之路。
相较既有的楷体汉字字符集研制,古文字字符集的研制必须完成如下几项“额外”任务。
第一,字符认定工作。一个字符集需要多少字符,对于通用楷体字符集研制来说,可以依据文字规范文件(如字典或字表)来确定。但是,古文字并没有这种文字规范,这就决定了古文字字符集研制需要以所有古文字文献用字为对象,逐字认定其字符资格,具体就是逐个确定需要进入字符集的字样,并认定每个字样所代表的实际文献用字。
第二,字符集中的字符与实际文献用字的逐字对应。对于楷体字字符集的研制来说,这个任务也是不存在的,这是因为,当下楷体文字的文本都是通过电脑输入法输入而形成数字文本的,而电脑输入法本身就是以通用字符集为字符来源的,因此所有文本中的用字都自带标准字符集的编码。古文字字符集则因为含有大量目前通用汉字字符集所没有的“集外字”,因此把它们在古文字字符集中的编码落实到对应文字材料中,让每个用字都带上统一且唯一的编码,字符集才可能具备数字处理的功能。
第三,字符的“原貌保真”。古文字字符的这种要求,与楷体字字符集的理念是完全不同的。因为楷体的汉字字符集只收入经过正字法规范、形体抽象归一、用于正式出版印刷的“正字”,而手写变化的原貌是被排除的。那么,古文字字符集是否也可以运用转字体方式来使用原形呢?答案只能是否定的。以《新甲骨文编(修订版)》为例略加具体说明。该字编的“正编”在“萅”字目上括注“春”这个通用字形。但即使加注了字形,也无法满足该字甲骨文的数字处理需要。

上述要求无疑给古文字字符集的研发提出了艰巨的任务,而之所以要承受此种付出,是因为古文字字符集会带来前所未有的古文字数字化效应。
开启古文字“冷门”的钥匙
一百多年前,王国维提出“二重证据法”,提倡运用“地下之新材料”与“纸上材料”的古文献记载相互印证,以考量古代历史文化。“二重证据法”的立论依据,就是我们祖先留下的文化遗产是以“地下”和“纸上”两种载体传承下来的。而所谓“地下材料”,主要是指古文字材料。作为传承中华文化两翼之一的古文字,以其相对年代更早且更真实地保存了文献的原始面貌,而成为中国文化遗产中最具历史厚度的部分。因而古文字成为冷门的现实,显然会造成中华文化传承的巨大损失。
古文字有着以字为单位的庞大知识系统,陈寅恪先生曾有“凡解释一字即是作一部文化史”的论说。当然,一个字的知识系统并不止于文化史,至少还有字和词的知识系统。而长期以来古文字知识的获取途径又极为不便,正所谓“为找一书,走遍天下;为查一字,翻遍全书”。这是前数字时代古文字处理手段极度落后(基本限于手抄)长期积累下来的现状。知识系统的庞大和传播手段的落后,乃是造就古文字冷门的基本原因。
互联网的知识传播平台,可以让人们轻点鼠标瞬间获得各个领域的专业知识。这本应对古文字信息的传播产生非常积极的影响。但事实上,古文字信息目前基本还处在互联网的盲区。而导致这一窘境的根本原因就是古文字字符集的缺位。有的国学知识学习网站,虽然也提供甲骨文知识检索,但仅是通过甲骨文著录书籍的甲骨片编号来查那片甲骨的图像和释文,而释文中的集外字只能用开天窗(统一用个框来表达)的方式显示。为什么不来个“全文检索”呢?当然就是因为没有字符集支持。
很显然,古文字字符集的出现,可以全方位改变这种窘境。古文字字符集可以以字符为单位,通过数字系联将相关的古文字知识聚合,字符则成为这一知识库的数字门户。笔者所在华东师范大学古文字网络数据库,正是利用所研发的古文字字符集,在提供集内字检索功能的基础上,又提供集外字检索路径。具体为:合体集外字通过偏旁检索,独体集外字通过笔画数检索。点击每个集外字,都可进入该字各次出现的古文字文例、释文、拓片或照片,以及考释研究信息。虽然这一数字窗口的建设还有继续完善的很大空间,但也已经显示了古文字字符集开启古文字冷门的强大能力以及未来发展的前景。
古文字字符集对古文字数字传播的支撑作用是全方位的,当然不会限于古文字网站建设这一个点。比如,近来颇为热闹的古文字图像识别等智能化研发,同样需要古文字字符集的支持,才有可能取得理想的成效。
启动古文字研究的数字模式
对于古文字本体研究来说,古文字字符集的出现,意味着我们可以实现各种古文字字符的数字处理,进而在穷尽材料生成大数据的前提下以定量方式完成古文字的各种研究任务,这种进步可以推动古文字各个方面的研究,甚至破解既有的瓶颈难题。限于篇幅,仅举一例。
孔子曰:“微管仲,吾其被发左衽矣。”(《论语·宪问第十四》)这一文献记载表明,中原华夏习惯上衣襟右掩,称为右衽;而异族崇尚左,衣襟左掩,是为左衽。类似记载还见于《尚书·毕命》以及后世诸多文献。
然而,近年来有学者以若干古文字字形(甲骨文字形: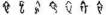 ,金文字形:
,金文字形: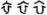 )为依据之一,对于上述“左衽”和“右衽”说的历史真实性提出质疑。提出:“由字形可知,衣襟相互叠压,或向左或向右,两种字体交互使用且并没有确定方向。因此,在甲骨文和金文创始之初,华夏族还不存在严格的左衽与右衽的区别,而且似乎右衽在当时还没有左衽流行。”(陶辉等《“披发左衽,华夷之辨”的考辨》,《装饰》2020年第7期)
)为依据之一,对于上述“左衽”和“右衽”说的历史真实性提出质疑。提出:“由字形可知,衣襟相互叠压,或向左或向右,两种字体交互使用且并没有确定方向。因此,在甲骨文和金文创始之初,华夏族还不存在严格的左衽与右衽的区别,而且似乎右衽在当时还没有左衽流行。”(陶辉等《“披发左衽,华夷之辨”的考辨》,《装饰》2020年第7期)
中国的古文字形是内涵极丰富的古代文化资源,然而对这一资源的科学运用,则需要系统把握其动态使用的各种信息,仅仅列举几个字形无法准确揭示其真实的文化内涵。而立足字符集来探究这一问题则可以获得更周全而准确的信息。笔者主编的《古文字构形类纂·金文卷》(上海辞书出版社即出,以下简称“类纂”)是一部以字符集标准编纂的商周金文构形工具书,商周金文是最规整的古文字类型,其长达千年的时间跨度又是各古文字种类之最,用以作为古代文化的研究材料显然是合适的。因此不妨依据相关的“类纂”金文构形分类(即字符集研制)成果,来重新探究“左衽”和“右衽”现象的历史真实性问题。

综上,就古文字字符集呈现的信息来看,华夏右衽的历史是可以得到证明的,至迟在春秋时期,这种习尚已经具有相当的影响力。
(本文系国家社科基金重大项目“基于公共数据库的古文字字符集标准研制”(21&ZD309)阶段性成果)
(作者单位:华东师范大学中国文字研究与应用中心)



